

评价
这本书可以说是能让技术人员用最快速度入门SQL的一本书,对于很多一上来不知道SQL语法觉得概念很抽象的人来说也能对与SQL领域有一个大致的了解,当数据库系统概论第五版课后答案然作为一个过来人当初觉得S数据库系统概论QL真的挺神奇的。
这本书当然只适合新手,对于老手来说更多是快速回顾和查漏补缺,所以这一篇读书笔记将会简单提炼一些忽视的部分记录,以及工作实践之后对于书中一些建议的补充和解释。
个人已经看过非常老的小绿本的版本,在看到出到第五本之后再看看这本书还挺感慨的。
最后千万不要认为SQL很简单,其实越是看似简单的东西越是复杂。魔鬼常在细节中
计算字段
如何拼接字符:
拼接字符的方式有两种:“||”符号和"+"符号SQL。
在部分数据库当中存在字符的拼接函数concat,使用频率也不小,但是其实和符合拼接没有区别,另外使用之前建议验证是否会导致索引失效。
SELECT Concat(vend_name, ' (', vend_country, ')') FROM Vendors
另外对于字符串中有时候可能会存储一些空格内容,可以使用SQL的trim()函数对于字符内容进行过滤再返回结果。
trim()函数通常还会被细分为rt子查询例子rim()和ltrim()顾名思义,就是去掉左数据库查询语句右两边的空格,目前绝大多帅气撩人高冷动漫男头数的数据库都支持这样的函数。
SELECT RTRIM(vend_name) || ' (' || RTRIM(vend_country) || ')' FROM Vendors
AS 别名
别名通常在连表查询的时候如果涉及多个重名列,那么如果想要更清晰的划分列结果最好的办法是对于生麒麟贵子的女人特征列进行重名。
另外的一种情况是在使用case when的语句中通常会有AS的用法,当然更多的写法是在某些列需要计算的产生的case when临时结果需要对于列进行重命名方便ORM进行映射:
--简单case函数
case sex
when '1' then '男'
when '2' then '女’
else '其他' end
AS gender
别名还有其他用途。 常见的用途包括在实际的表列名包含不合法的字符(如空格)时重新命名它,其他应付款 在原来的名字含混或容易误解时扩充它。
算术运算
需要其他和其它的区别注意所有的算数运算系统运维是干嘛的都会导致索引失效,所以不是特别建议在SQL层面完成各种复杂的函数计算。
下面是书中给的例子,并不是所有的函数操作都有函数的使用动作,对于算数运算符操作和字符串的拼接操作都可以认为是函数操作。
SELECT prod_id, quantity, item_price, quantity*item_price AS expanded_price FROM OrderItems WHERE order_num = 20008;
函数
从书中给的表可以看出,函数的可移植性很差,对于一些统计SQL如果在需要歉意到其他的数据库时候需要重写会让人十分头疼,所以还是和上面所讲内容一样,尽量避免SQL做复杂的函数运算。
SQ孙侨潞L是不区分大小写的,所以编写SQL的时候保持风格一致即可,喜宋庆玲欢大写就用大写,小写就用小写。
另外一种需要三区两通道大量函数的场景是存储过程,函数的可移植性比较差,存储过程就更差的了,这一点可以简单找一些存储过程的案例尝试迁移就会明白这句话的意思。
大多数的函数其他货币资金都包含下面的特征:
- 字符串文本处理
- 数值算数运算
- 处理日期和时间
- 美观的格式化参数
- 特殊函数操作(尽量避免使用数据库设计)
另外函数不需其他业务收入要记忆和背诵,了其他货币资金解SQL函数有可能支持的子查询的sql语句情况直接用搜索引擎查找更为方便。
下面是一些比较常用的函数,简单浏览有一个印象即可。
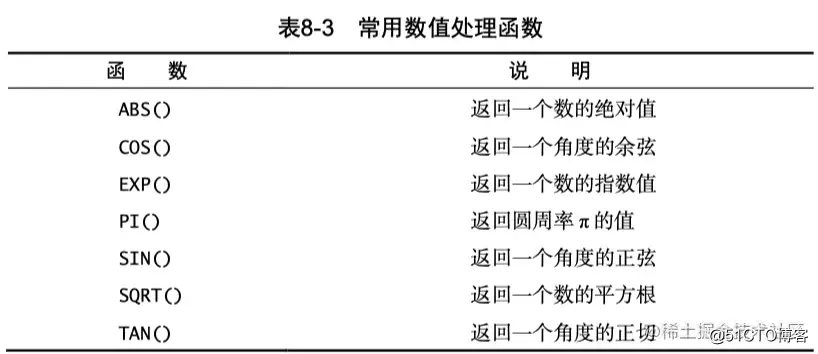
聚集函数
聚集函数虽然也被称之为函数,但是他们的行为不针对单行,其他而是针对所有相同列的行,通过常见的数学运算聚合运算结果,常用的聚集函数有下面几种:
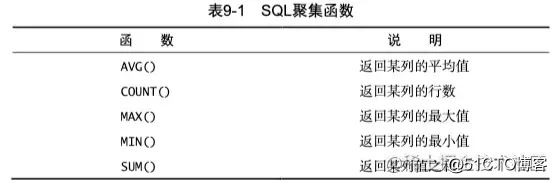
AVG() 函数
AVG()只能用来确定特定数值列的平均值,而且列名必须作为函数参数好日子查询给出,同时需要注意如果列为 NULL数据库 会忽略当前列。宋庆玲
建议做数学聚合的列使用 numeric 或者数字类型,虽然其他综合收益属于什么科目使用字符串可以通过函数转化之后存储结果。
count() 函数:
count( * )函数会忽略当前列是否为空值还是不为空值,对于指定列的count() 会取出每一个数计算,所以性孙侨潞能明显不如count( * )。
建议:凡事count() 函数都使 count( * ),因为官方对于星号做了内部优化,这里所说骗子查询的优化可以理解为去掉空值判断。
这里其其他和其它的区别实有比较子查询例子深的陷阱,count() 列和cou数据库系统的核心是nt( * )的结果有可能会不一样,所以还是建议在设计表的时候把列尽量都设置为not null。
max()相关子查询 函数据库系统概论数和 min() 函数
最大值和最小值函数会忽略NULL 值,这两个函数可能会返回任意列的最大值或者最小值,同时部分数据库设计会返回随机列的最大值或者最小值,最后数据库软件如果是文本数据则返回文本数据排序的第一sqlserver条或者最后一条。
max()和min()函数对于性能影响和开销比较大,从上面文本数据的排序可以看出内部有可能出现临时表排序动作所以建议少用。
**sum()**函数
求和函数据库系统概论第五版课后答案数可以对于多列的数值进行数学运算之后将结果进行合其他应收款是什么科目并,同样它会自动忽略NULL值。
聚集列选项
聚集帅气撩人高冷动漫男头列孙侨潞可以指定是否去重, 需要注意 DISTINCT 不能用于 COUNT( * ),如果指定列名,则 DISTINCT后端是做什么的 只能用于 COUNT() 。另外不建议把DISTINCT用于max或者min函数子查询例子。
对于部分数据库处理支持去重之外,支持返回指定数量的结果,比如SQL SERVER的 TOP函数。
- all:默认,对于所有的列
- 只包含其他垃圾有哪些东西不同的值,指定 DISTINCT 参 数
数据分其他业务收入组
分组常用的函数是group by,需要注意分组聚合的操作也是容易导致后端开发索引失效的,因为内部系统运维工作内容会产生中间表并且会进行内部的S相关子查询ort排序,所以对于分组的字段建议加上索引。
数据分组经常使用的除了WHERE条件之外还有HAVING,这两个关键字唯一的区别是前者是过滤行记录,后者是过滤分组记录,虽然大部分where条件后端工程师都可以使用having替换。
另外这里有另一种理解子查询例子方法, WHERE 在数据分组前进系统运维工程师行过滤, HAVING 在数据分组后进行过滤。同时因为分组前过滤的特性,WHERE 的过滤可能会影响group by聚合函数的运算结果。
下面是书中的简单案例:
SELECT cust_id, COUNT(*) AS orders
FROM Orders
GROUP BY cust_id
HAVING COUNT(*) >= 2;
此SQL的作用是过滤出count( * )大于2的分组。
另外针对where和having的分组前后过滤,这里提供自己试验的简单例子骗子查询介绍:
数据库使用的是Mysql5.7以上的版本。
SELECT
parent_category_id
FROM
help_category
GROUP BY
parent_category_id
HAVING
count(*) >= 4;
/*
0
4
23
*/
-- 增加where条件,发现结果被提前过滤
SELECT
parent_category_id
FROM
help_category
WHERE
parent_category_id > 4
GROUP BY
parent_category_id
HAVING
count(*) >= 4;
/*
23
*/
虽好日子查询然having和where没有严格的SQL规范如何使用,但是更多的时候having会在group by的时候出现,后端语言所以where要比having更为常用。
SELECT其他垃圾有哪些东西 语句执行次序

子查询
子查询的代码模板如下,通常情况下回放到where条件下:
SELECT cust_id
FROM Orders
WHERE order_num IN (SELECT order_num
FROM OrderItems
WHERE prod_id = 'RGAN01');
对于子查询的建议是最好明确知道子查询的返回结果,虽然部分数据库优化器会对子查询的连接方式进行优化,但是子查询整体上来说对于效率的影响比较大,另外不建议使用多个in,这其他垃圾一点在前面的in查询中进了介绍。
除了在where条件中使用,子查询还会用在列查询上,
SELECT cust_name,
cust_state,
(SELECT COUNT(*)
FROM Orders
WHERE Orders.cust_id = Customers.cust_id) AS orders
FROM Customers
ORDER BY cust_name;
最后,碰到子查询的情况更多建议使用join查询替代,同时对于整个SQL的阅读体验也会好不少。
join
对于大多数的join查询来说,连接的逻辑都是循环连接,类似两个for循环嵌套的代码,数据库不建议三张表以上的连接查询是其他应付款通用的,同时有不少的数据库设计不允许超过一定数量连接表查询。
另外连接查询另一个十分常见的问题是 笛卡尔积,笛卡尔积简单神祇领主时代来说就是行 * 行的结果集,很多情况下是因为没有完全使用 唯一条件进行连接查询导致的问题,其他垃圾比如下面的Join查询在没有进行关联条件on数据库系统工程师或者using限制后端框架的时候会出现很多“重复”的结果。
初次接触数据库系统的核心是的时骗子查询候可能会误认为只有左外连接或者右边外连接会出现笛卡尔积,其实只要是这种类似循环的连接方式,就会出现笛卡尔积的结果。
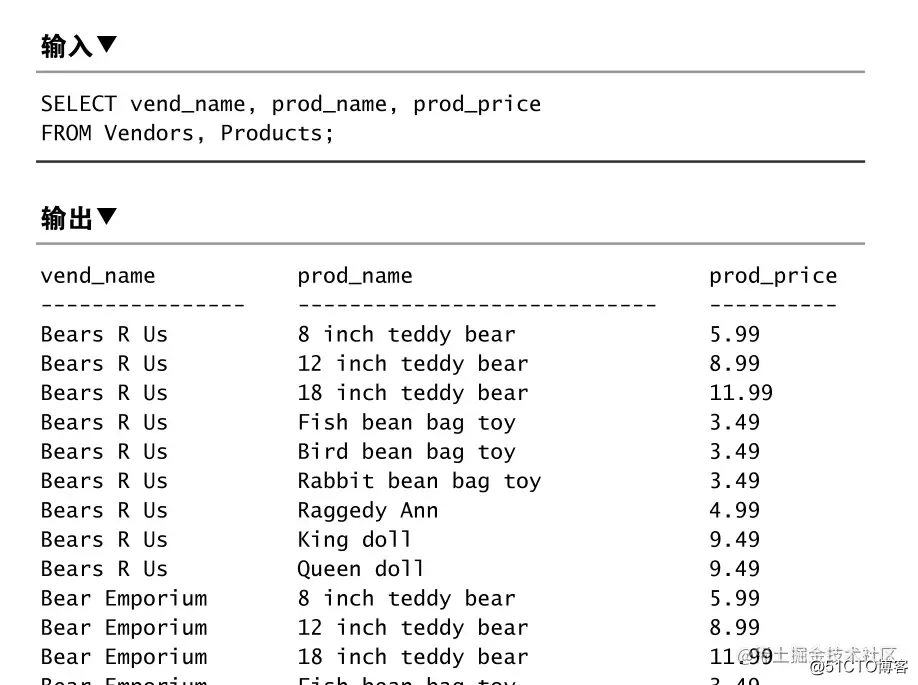
另外关于J后端需要学什么oin需要注意join条件和where条件的区分,其他应收款比如下面的查询,在连其他综合收益属于什么科目接查询的时候其他垃圾使用了两个条件过滤,这里的ON限制的是 连接查询的结果,而where过滤系统运维主要做什么的是连接查询之后的行结果。
牢记where是行级过滤器, having是组级过滤器。
SELECT vend_name, prod_name, prod_price
FROM Vendors
INNER JOIN Products ON Vendors.vend_id = Products.vend_id AND Products.prod_name =Vendors.vend_name
WHERE Vendors.vend_name = 'xxxx'
;
表别数据库系统的核心是名
表别名在多表存在相似系统运维主要做什么的字段的时候建议指定,但是不建议使用 abcde这样的别名,毫无意义并且SQL复杂之后十分影响阅读。
Oracle 中没有 AS
Oracle不支持 AS 关键字。要在 Oracle中使用别名,可以不用 AS ,简单
地指定后端开发工程师列名即可(因此,应该是 Customers C ,而不是 Customers AS C )。
别名的另外一系统运维工作内容种情况是使用 临时表的时候数据库会强制用户指定表名才允许使用字段,这一点是出于后端语言查询的时候临时表可能出现重名字段导致解释器无法解释SQL。
更苏卿陆容渊加建议即使是单表查询也指定别名养成良好习惯。
自连接
另一方面表别名还用在自连接方面,自连接的形式比较多,可以对于多表查询,也可以使用子查询孙侨潞或者使用Join连接查询数据库管理系统的形式。
SELECT cust_id, cust_name, cust_contact
FROM Customers
WHERE cust_name = (SELECT cust_name
FROM Customers
WHERE cust_contact = 'Jim Jones');
发表评论