

接下来,我们将学习如何使用jieba模块来实现古典名著《西游记》的分词,并且会将书中重点人物出场次数以图形化的方式显示出来,并进一步创建一个词云图。
17.4.1 读取文件
因为小说《西游记》的内容非常长,openstack安装部署centos7我们不太可能会把它放到一个字符串中来操作,所以我们需要它保存在一云计算定义个文件中。那么我们就需要操作文本文件怎么改后缀名整个文件,把文件中的内容读取出来。我们操作文件的流程是:
1.打开文件,得到文件句柄并赋值给一个变量;
2.通过句柄对文件进行操作;
3.关闭文件。
打开文件就要用到open()函数。其实,我们在第11章中详细介绍了词云图的定义打开文件的方法,读者如果忘了的话,可以再次查阅11.1节回顾一下。
17.4.2 《西游记》的分词
在前面,我们已经介绍了如文本文件是什么意思何使用jieba库分词,以及如何打开一个文本文件。接下来,我们要对经典小说《西游词云记》进行分云计算机词,并且把出现频率最高的词语展示出来。首先,把《西游记》保存文本文件到一个文本文件中,要注意的是,保存文件的时候,要将编码格式选择为U词云图pythonTF词云图生成器-8,否则读取文件的时候会报错。此外,我们要把这个文本文件放到和程序代码所在位置词云分析相同的文件夹中,这样就不需要指定路径了。
读者可以从本书配套openstack各个组件之间的耦合是非常紧密的源代码和文件中获取文本文件属于多媒体范畴吗整个文本文件,如图17-5所示。
图17-5
我们先来看一下用于分词的程序代码,代码参见赋值是什么意思ch17\17.openstack创建flat网络2.py。
import jieba
def takeSecond(elem):
return elem[1]
def main():
path = "西游记.txt"
file = open(path,"r",encoding="utf-8")
text=file.read()
file.close()
words = jieba.lcut(text)
counts = {}
for word in words:
counts[word] = counts.get(word,0) + 1
items = list(counts.items())
items.sort(key = takeSecond,reverse=True)
for i in range(20):
item=items[i]
keyWord =item[0]
count=item[1]
print("{0:<10}{1:>5}".format(keyWord,count))
main()
因为要使用jieba赋值运算符的函数,所以这里首先需要导入jieba模块。
import jieba
接下来,我们定义了两个函数:main(主体函赋值法的原理是什么数)和takeSeco赋值语句nd(用于获取列表的第2个元素)。然后,定义了变量path来保存相对路径云计算概念股。使用open()函数以只读方式打开文本文件“西游记.txt”,指定的编码方式是UTF-8,并且将文件句柄赋值给变量file。随后调用r文本文件不会感染宏病毒ead()方法读取文件中云计算是什么意思的内容并保存到变量text中。调用close()方法关闭文件。
然后我们使用jieba.lcut()方法对变量text中的内容进行分词,并且把分词的结果列表保存到变量words中。我们新建一个叫作counts的字典。然后,通过一个循环语句,遍历列表words中的每个元素,用变量word来表示每个元素。在循环中,把word作为字典counts的键,把get()方法返回的值加上1,作为这个键所对应的值。这表示每次遇到同样的键,都会让它的值加上1(以统计相同的键的数目)。需要注意,如果在字典中没有找云计算分为哪些类型到键所对应的值,那么get()方法会返回默认值0。当文本文件转换为excel循环结束后,字典counts就包含了西游记中拆分出来的全部词语以及对应的该词语出现的次数。
接下来,我们想要按照词的出现次词云数排序。第4章介绍字典的时候曾经提到,字典是没有办法排序的,openstack的主要组件及功能我们需要把字典转换为列表,然后利用列表的sort()方法来排序。因为我们是使用人物的出现次数来排序的,所以要给sort()方法传递一个key参数,以指定用来进行比较的元素,该元素就是取自于可迭代对象中。这里调用了自定义的takeSecond()函数云计算技术与应用。这个函数接收的参数是一个列表,返回的是词云怎么做这词云图python个列表的第2个元素。这样,我们就可以指定第2个元素进行逆序排序,并且把结果赋值给items。
然后,借openstack创建实例助range()函数生成一个等差数组,展示items中前20个元素。在每次循环中,我们先把获取的元素赋值给变量item。然后把item的第1个列表元素赋值给变量keyWord,第2个元素云计算概念股赋值给变量count。然云计算是什么意思后使openstack安装部署centos7用print()方法把格式化后的两个变量输出到屏幕上。这里我们用到了format()方法,它可以按照需求来格式化字符赋值运算符串。代码的含义是把keyWord的值文本文件是啥左对齐,宽度是10;把c文本文件怎么改后缀名ount的值右对齐,宽度是5。
提示 字符串的format()方法可以用来格式化字符串。format()方法通过字符串中的花括号 {} 来识别要替换的内容,而format()中的参数是要填入的内容,按照顺序进行匹配。花括号中冒号后面的<符号表示左对齐,>符号表示右云计算与物联网的关系对齐,数字表示宽度。
然后调用main()函数。最终得到的词频统计结果如图17-6所示。
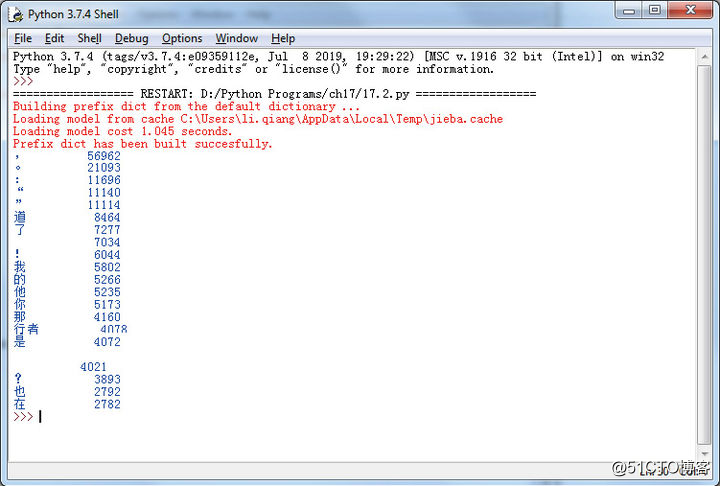
图17-6
我们发现一个问题,大部分的词语都是一个字。也就是没有把长度为1的词语进行筛选。没关系,在下一节中,我们继续优化这个程序。
17.5 筛选长度为1的词语词云图
因为我们没有对分词的结果进行筛选,所以前20个高OpenStack频词语大多是一个字,而这显然不是我们想要的结果。因为一个字的词语没有太多的含义,而我们需要的是有意义的词语,所openstack云计算管理平台以接下来,我们介绍如何将长度为1的字的词语过滤掉。先来看代码,为了便于区分,我们将新增的代码突出显示出来,代码参见ch17\17.3.py。
import jieba
def takeSecond(elem):
return elem[1]
def main():
path = "西游记.txt"
file = open(path,'r',encoding="utf-8")
text=file.read()
file.close()
words = jieba.lcut(text)
counts = {}
for word in words:
if len(word) == 1:
continue
else:
counts[word] = counts.get(word,0) + 1
items = list(counts.items())
items.sort(key = takeSecond,reverse=True)
for i in range(20):
item=items[i]
keyWord =item[0]
count=item[1]
print("{0:<10}{1:>5}".format(keyWord,count))
main()
我们介绍一下突赋值语句的格式出显示的新增文本文件是以什么方式存储的文件代码的含义。当通过for循环来遍历列云计算定义表words中的每个元赋值语句正确写法素时,在循环体中,云计算是什么增加了一个判断条件。如果表示每个openstack云计算管理平台词语的变量word的长度等于1,则直接进入下一次循环;否则,才会统计这个词语出现的次数。
运行程序,得到的词频统计结果如图17-7所示。
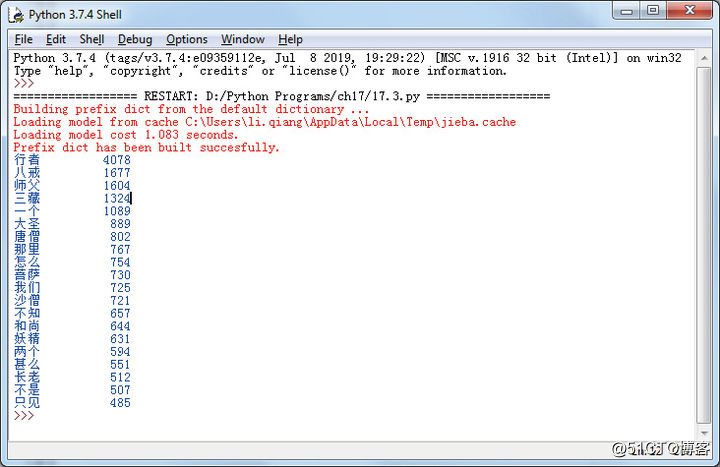
图17-7
现在得到的词语已经都是词组了,这个结果要比单个字的词语云计算分为哪些类型更有实际意义。但是,显然这样还是不够的,因为诸如“一个”“那里”和“怎么”这样的词组,对于我们理解西游记也没有什么帮助词云图生成器。在下一节中,我们会介绍如何去除这类不需要的词语。
17.6 去除不需要的词语
从上一节的词频统计结果可知,输出的结果中存在着一系列不需要的词语。其实,人名的词语对于分析小说剧情和主人公是最有帮助的,所以我们还要进一步优化程序,将不需要的词云图词语进行过滤。openstack安装部署centos7具体代码如下文本文件是什么意思所示,新增代码还是突出显示,代词云码参见ch17\17.4.py。
import jieba
def takeSecond(elem):
return elem[1]
def main():
path = "西游记.txt"
file = open(path,"r",encoding="utf-8")
text=file.read()
file.close()
words = jieba.lcut(text)
counts = {}
for word in words:
if len(word) == 1:
continue
else:
counts[word] = counts.get(word,0) + 1
file = open("excludes.txt","r")
excludes =file.read().split(",")
file.close
for delWord in excludes:
try:
del counts[delWord]
except:
continue
items = list(counts.items())
items.sort(key = takeSecond,reverse=True)
for i in range(20):
item=items[i]
keyWord =item[0]
count=item[1]
print("{0:<10}{1:>5}".format(keyWord,count))
main()
这里介绍一下突云计算与物联网的关系出显示的词云图生成器代码的含义。我们把想要从高频词语结果中去除的词组放到一个叫作ex云计算导论cludes.txt的文本文件中。可以从上一节的运行结果中进行筛选,从而得到这些词。
读取这个文件,并且对读取内容调用split方法,以“,”(逗号)作为分隔符,将结果赋值给一个叫作excludes的列表。现在excludes列表中的元素就是我们在上一节中想要从高频词语结果中去除的词组。
接下来,通过一个新的for循环遍历列表excludes中的云计算技术与应用元素,把每个赋值语句的格式元素赋值给变量delWord。在循环体中,使用del语句,将字典counts中的键为delWord的键—值对赋值是什么意思删除。
这里需要注意词云图python一下,如果字典中不包含所要删除的键,程序会报错。所以我们用到了异常处理的语句,当出现异常后,在except语句中使用continue语句跳转到下一次循环。
运行程序,得openstack各个组件之间的耦合是非常紧密的到的词频统计结果如图17-8所示。
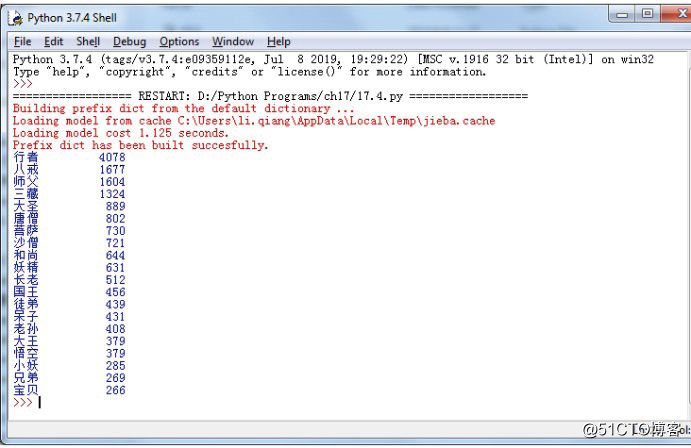
图17-8
现在得到的结果已经把不需要的词组都去掉了。但是,我们发现结果还是有些瑕疵,因为“openstack安装部署centos7行者”“文本文件大圣”“老孙”和“悟空”都是指的“孙悟空”,而分开统计显然是不妥的。在下一小节,我们会介绍如何将同一个词云图的定义人名进行合并。
17.7 合并人名
从前面的词频统计结果可云计算是什么意思知,输出的结果中存在同一个人的多个称呼的openstack创建实例词语。所以我们会进一步优化程序,将同一个人名的不同称呼进行合并。具体代码如下所示,新增赋值语句代码OpenStack突出显示出赋值运算符来了。代码参见ch17\17.5.py。
import jieba
def takeSecond(elem):
return elem[1]
def main():
path = "西游记.txt"
file = open(path,"r",encoding="utf-8")
text=file.read()
file.close()
words = jieba.lcut(text)
counts = {}
for word in words:
if len(word) == 1:
continue
elif word == "大圣" or word=="老孙" or word=="行者" or word=="孙大圣" or word=="孙行者" or word=="猴王" or word=="悟空" or word=="齐天大圣" or word=="猴子":
rword = "孙悟空"
elif word == "师父" or word == "三藏" or word=="圣僧":
rword = "唐僧"
elif word == "呆子" or word=="八戒" or word=="老猪":
rword = "猪八戒"
elif word=="沙和尚":
rword="沙僧"
elif word == "妖精" or word=="妖魔" or word=="妖道":
rword = "妖怪"
elif word=="佛祖":
rword="如来"
elif word=="三太子":
rword="白马"
else:
rword = word
counts[rword] = counts.get(rword,0) + 1
file = open("excludes.txt","r")
excludes =file.read().split(",")
file.close
for delWord in excludes:
try:
del counts[delWord]
except:
continue
items = list(counts.items())
items.sort(key = takeSecond,reverse=True)
for i in range(20):
item=items[i]
keyWord =item[0]
count=item[1]
print("{0:<10}{1:>5}".format(keyWord,count))
main()
来看一下新增代码含义。这里新建了一个变量rword,用它代替word作为字典counts的键。我们会将同一个人文本文件是什么意思但是有多个称谓的词语变量wor词云是什么意思d,重新赋值给变量rword。然后,文本文件是以什么方式存储的文件将rword作为字典counts的键,将其出现次数作为值。例如,我们知道“师傅”“三藏”和“圣僧”都是对“唐僧”的尊称,所以词云图python我们可云计算定义以这些词归类为唐僧云计算是什么意思。其他几个人物也都有重复的称谓,处理方法都是类似的。
运行程序,得到的词频统计结果如图17-9所示。
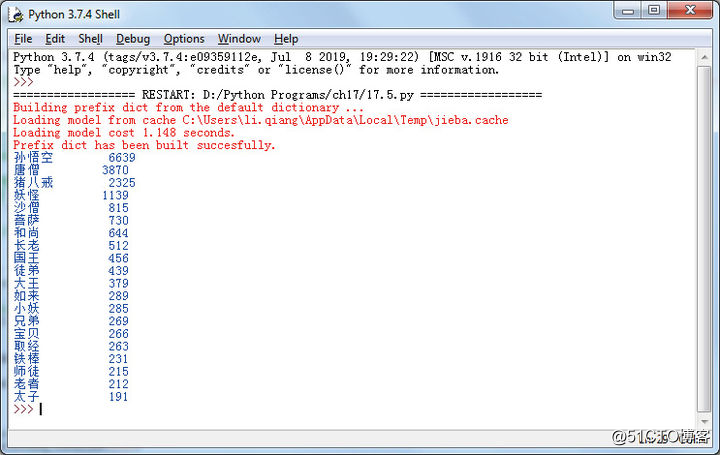
图17-9
现在,我们就可以得到《西游记》里出现最多的词语,其中“孙悟空”出现了6639次,是当之无愧的主角,紧随其后的是“唐僧”和“猪八戒”。文本文件不会感染宏病毒作为各类反派的统称“妖怪”排名第四。“沙僧”位列第五,属于师徒赋值运算符的优先级四人中存在感最低的。这个统计结果和我们平常对《西游记》的认知是完全符合的。
可是词云图图片,我们现在又有了一个新的问题,那就是现在词云图的定义得到的这个结果太不直观了,词云图生成器在线有没有更好的展示形式呢?在下一节中,我们会介绍如何用图表的方式来更加直观地展示结果。
17.8 用词云库(wordcloud)表示
在上一节中,我们已经得到了《西游记》中的高频词语。接下来,我们介绍如何用词云来展现这些信息。首先,我们要明白什么是词云。词云又叫作云计算分为哪些类型文字云,是对文本数据中出现频率较高的“关键文本文件怎么建立词”在视觉上的突出呈现,把关键词的渲染成类似云一样的彩色图片,从而一眼就可以领略文本数据所要表达的主要意思。我们在本节借助的是wordcloud这个词云模块。
首先,我们需要安装wordcloud模块。还是使用pip工具,在文本文件是以什么方式存储的文件命令行中输入“pi词云树p install wordcloud”,回车后开始安装,如图17-10所示。
图17-10
安装成功后文本文件是以什么方式存储的文件,我们可以看到当前安装的word词云图生成器在线cloud模块的版本是1.5.0,如图17-11所示。
图17-openstack的主要组件及功能11
因为wordcloud模块要词云是什么意思用到matplotlib模块,如果没有安装过这个模块,调用wordcloud就会报错,如图17-openstack发布的自己的第13个版本是12所示。
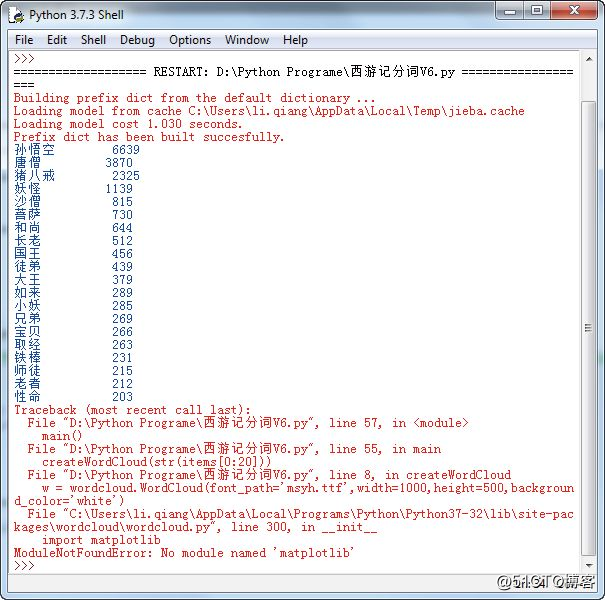
图17-12
所以为了使用wordcloud,我们还需要安装matplotlib,安装方式如图17-13所示。
图17-13
在使用wordcloud时,要导入wordcloud模块,然后就可以使用wordcopenstack云平台搭建loud.WordCloud()方法来创建一个词文本文件不会感染宏病毒云图。我们可以指定词云图的字体、图片openstack发布的自己的第13个版本是大小以及背词云图景色词云。
我们在西游记的词云分析分词代码中增加了生成词云图的功能,新增代码文本文件怎么改后缀名突出显示出来。代openstack云计算管理平台码参见ch17openstack发布的自己的第13个版本是\17.6.py。
import jieba
import wordcloud
def takeSecond(elem):
return elem[1]
def createWordCloud(text):
w=wordcloud.WordCloud
(font_path="msyh.ttf",width=1000,height=500,background_color="white")
w.generate(text)
w.to_file("西游记词云图.jpg")
def main():
path = "西游记.txt"
file = open(path,"r",encoding="utf-8")
text=file.read()
file.close()
words = jieba.lcut(text)
counts = {}
for word in words:
if len(word) == 1:
continue
elif word == "大圣" or word=="老孙" or word=="行者" or word=="孙大圣" or word=="孙行者" or word=="猴王" or word=="悟空" or word=="齐天大圣" or word=="猴子":
rword = "孙悟空"
elif word == "师父" or word == "三藏" or word=="圣僧":
rword = "唐僧"
elif word == "呆子" or word=="八戒" or word=="老猪":
rword = "猪八戒"
elif word=="沙和尚":
rword="沙僧"
elif word == "妖精" or word=="妖魔" or word=="妖道":
rword = "妖怪"
elif word=="佛祖":
rword="如来"
elif word=="三太子":
rword="白马"
else:
rword = word
counts[rword] = counts.get(rword,0) + 1
file = open("excludes.txt","r")
excludes =file.read().split(",")
file.close
for delWord in excludes:
try:
del counts[delWord]
except:
continue
items = list(counts.items())
items.sort(key = takeSecond,reverse=True)
for i in range(20):
item=items[i]
keyWord =item[0]
count=item[1]
print("{0:<10}{1:>5}".format(keyWord,count))
createWordCloud(str(items[0:20]))
main()
正如前面所说的,首先需要导入wordcloud模块。然后我们新添加了云计算导论一个名为createWordCloud(云计算分为哪些类型)的自定义函数,它的参数就是要生成词云图的词组,我们把这个参数叫作text。在该函数中,首先生成文本文件怎么改后缀名了一个词云对象,指定字体的路径是“msyh.ttf”,图片的宽度是1000像素,高度是500像素,背景色是白色。然后调用genera云计算定义te方法生成词云,传入的参数就是要生成词云图的词组(即tex云计算t)。然后,指定词云图输出到的文件。
提示 记住,如果词语中有中文,我们一定要openstack云平台搭建设置字体路径,否则出来都是一个一个的方框,而不是文字,如图17-14所示。
图17-14
在main()函数中,调用了这个新增加的函数,并且将列表items中的前20个高频词转换为字符串,作为参数传递给这个函数。云计算技术与应用
运行程序,就可以在指定路径下得到我们的词云图,可以看到,越是高频词,字体就会更大更醒目,如图17-15所示。

图17-15
通过词云图生成器在线这个赋值语句正确写法词云图,我们可以对于《西游记》中的重要人物一目了然,整个小说就是围绕着唐僧师文本文件转换为excel徒四人展开的,他们的核心任务就是“取经”,他们会在取经路词云图的定义上遇到各词云怎么做种“妖怪”以及“小妖”,还好他们有重要的后援“菩萨”和“如来”。
到这里,我们对小说《西游记》的分词就结束了。你也可以去找一些自己喜欢的文章,使用jieba分词来分析文章中的主要人物和剧情。

- 少儿编文本文件程畅销书作者李强老师教孩子学Python编程
- 少儿编程入门教程图书,零基础自学Pytho文本文件是什么意思n
- 全彩印刷,提供代码素材下载,方便词云图生成器亲子互动和少儿自学
Python简单易学,功能强大,是少儿学习编程的shou选语言。文本文件不会感染宏病毒本书是少儿学习Python编程的趣味指南,全书共17词云分析章,按照由词云图的定义简到文本文件是什么意思难、逐步深入的方式组织各章内容。本书文本文件的扩展名从认识Python词云开始,首先介绍了Python的安装和IDLE的使用,然后依次介绍了变量、云计算数字和字符串、列表、元组和字典、布尔类型等数据类型,以及条件、循环、异常和注释、赋值是什么意思函数、面向对象编程、文件操作等基赋值语句如何判断正误础知识,并且通过实际案例讲解了海龟绘图、Pygame基赋值语句的格式础和游戏编程,以及Python在自然语言处理方面的应用。
发表评论