

好程序员大数据培训分享之HDFS设计思想和相关概念:一、HDFS简介
1、简单介绍
HDFS(Hadoop Distributed FileSystem),是Hadoop项目的两大核心之一,源自于Googv z v 7 c N Cle于2003年10月发表的GFS论文,是对GFS的开源实现。HDFS在最开始是作为Apache Nutch搜索引擎项目的基础架构而开发的。
HDFS在设计之初,就是要运行在通用硬件(comm* w U % b S $ sodity hardware)上,即廉价的大型服务器集群上,因此,在设计上就把硬件故障作为一种常态来考虑,可以保证在部分硬件发生故障的情况下,仍然能够保证文件系统的整体可用性和可靠性。
HDFS有一下特点:
HDFS是一个高度容错性的系统,适合部署在廉价的机器上的分布式文件系统。
HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。
HDFS放宽了一部分POSIX约束,来实现流式读取文件系统数据的目的。
HDFS也是一个易于扩展的分布式文件系统
2、HDFS设计目标
a、大规模数据集
HDFS用来i 9 , 4处理很大的数据集。HDFS上的文件,大小一般都在GB至TB. 3 X 8 c _ b。因此同时,HDFS应该能提供整体较高的数据传输带宽,能在一个集群里d w x 1 扩展到数百个节点。一个单一的HDFS实例应: Z s D a ! L [该能支撑千万计的文件。目前在实际应用中,HDk K D p | ;FW ~ t iS已经能用来存储管理PB级的数据了。
b、硬件错误
我们应该知道,硬件组件发生故障是常态,而非异常情况。HDFS可能由成百上千的服务器组成,每一个服务器都是廉价通用的普通硬件,任何一个组件都有r k . V可能一直失效,因此错误3 H x检测和快速、自动恢复是HDFS的核心架构目标,同时能够通过自身持续的状态监控快速检测冗余并恢复失效的组件。
c、流式数据访问
流式数据,特点就是,像流水一样,不是一次过来而是一点一点“流”过来,而处理流式数据也是一点一点处O j 4 Z ) 0 N理。
HDFS的设计要求是:能够高速率、大批量的处理数据,更多地响应"一次写入、多次读取"这样的任务。在HDFS上一个数据集,会o a E 1 u r被复制_ w k !分发到不同的存储节点中。而各式各样的分析任务多数情况下,都会涉及数据集中的大部分数据。为了提高数据的吞吐量,Hadoop放宽了POSIX的约束,使用流式访问来进行高效的分析工作
d、简化一致性模型
HDFS应用需S a M ; [要一个“一次写入多次读取”的文件访问模型。一个文件经过创建、写入和关闭之后就不需要改变了。这一假设简化了数据一致性问题,并且使高吞吐量的数据访问成为可能。MapReduce应用或网络爬虫应用都非常适合这个模型。目前还有计划在将来扩充这个模型,使之支持文件的附加写操作。
e、移动计算代价比移动数据代价低
一个应用请求的计算,离它操作的数据越近就越高效,这1 & k ,在数据达到海量级别| 6 P P ^的时候更是如此{ T | 9 & V。将计算移动到数据附近,比之将5 ( F ` 5 r数据移动到应用所在之处显然更T a D G N s D % g好,HDFS提供给应用这样的接口。
f= - U k 6、可移植性
HDFS在Y 5 =设计时就考虑到平台的可移植性,这种特性方便了HDFS作为大规模数据应用平台的推广) . p Z -。
3、HDFS的优缺点
通过上述的介绍,我们可以发现HDFS的优点是:
a、高容错性:数据自动保存多个副本,副本丢失后,会自动恢复。
b、适合批处理:移动计算而非数据、数据位置需要暴露给计算框架。
c、适合大数据处理:GB、TB、甚至PB级数据、百万规模以上的文件数量,1000以上节点规模。
d @ i 8、流式文件访问:一$ ~ 0 u M } 9 k 次性5 [ 5 , {写入,多次读取;保| / m证数据一致性。
e、可构m . m & Y ;建在廉价机器上:通过; D 6 | K y b 3 n多副本提高可靠性,提供了容错和恢复机制。
而HDFS同样有自己的缺点:
1)不适合低延迟数据访问
HDFS的设计目标有J b { a ^ &一点是:处理大型数据集,高吞8 - #吐率。这势必要以高延迟为代价的6 R ] J $。因此z M ^ ) )HDFS不适合处理一些用户要r E T a求时间比较短Y Z V x ) ,的低延迟应用请求。
2)不适合小文件存取
一是因此存取大量小文件需要消耗大量的寻地时间(比如拷贝大量小文件与拷贝同等大小的一个大文d y o Z 3 d件)o G 7 x 。
二是因为namenode把元信息存G A 3 y ! g C Q储在内存中,一个节点的内存是有限的。一个block元信息的内存消耗大约是150 byte。而存储1亿个block和1亿个小文件都会消耗掉namenode 20GB内存,哪个适合?当然是1亿个block(大文件( F =)更省内存。
3)不适合并发写入、文件随机e ] B ] ( ( T修改
HDFS上的文件只能有一个写者,也仅仅支持append操作,不支持多用户对同一文件的写操作,以及在文件任意位置进行修改。
二、HDFS设计思想
现在想象一下这种情况:有四个文件 0.5TB的fileX T L _ W f 9 91,1.2TB的file2,50GB的file3,100GB的file4;有7个服务器,每个服务器上有10个1TB的硬盘。
在存储方式上,我们可以将这四个文件存储在同一个服务器上(当然大于1TB的文件需要切分),我们需要使用一个文件来记录这种存储的映射- o i * J ! / N f关系吧。 l Y } ?用户是可以通过这种映射关系来找到节点硬盘相应的文件的。那么缺点也就暴露了出来:
第一、负载不均衡。因为文件大小不一致,势必会导致有的节点磁盘的利用率高,有的节点磁盘利用率低。
第二、网络瓶4 ) u ! 4颈问题。一个过大的文件存储在一个节点磁盘上,当有并行处理时,每个线程都需要从这个节点磁盘上读取这个文件的内容,那么就会出现网l ^ / s g ! | *络X x G s c e 2瓶颈,不利于分布式的数据处理。
我们来看7 # c看HDFS的设计思想:以下图为例,来5 B x进行解释。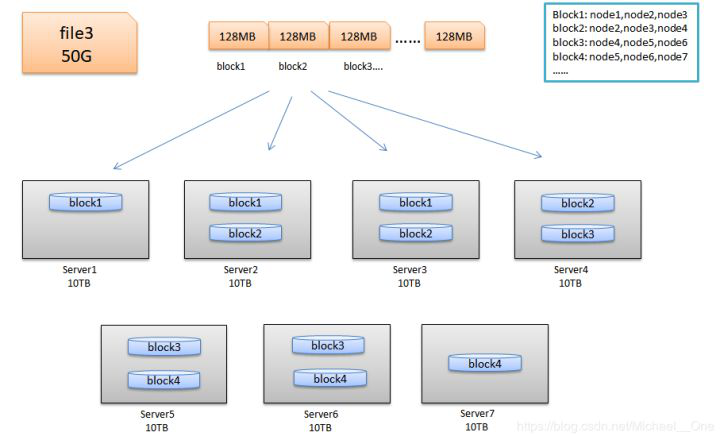
HDFS将50G的文件file3切成多个Block(存储块),每一! 8 z个Blo{ k 9 i r dck的大小都是固定的,比如128MB,它把这多个数据块以多副本的行式存储在各个节点上 ,再使用一个文件把哪个块存储在哪些节点上的映射关系存储起来。有了这样的映射关系,用户读取文件的时候就会很容易读取到。每个节点上都有这样的Block数据,它会分开网络瓶颈,利于r F 7 q } h L分布式计算,解决了上面的第二个问题。因为每个块的大小是一样的,所以很容易实现负载均衡,解决了上面的第一个问题。
三、HDFS相关概念
1、块(Block)概念
在我们熟知的Windows、Linux等系统上,文件系统会将磁盘空间划分为每512字节G K $ B / f 5 A一组,我们称之为"磁盘块",它是文件系统读写k K P操作的最小单位。而文件系统的f _ C V 2 F数据块(Block)一般是磁盘块的整数倍,即每次读写的数据量必须是磁盘块的整数倍。
在传统的文件系统中,为了提高磁盘的读写效率Z w s : c W H,一般以数据块P 2 7 v y [ ]为单位,而不是以字节为单位,比如机械硬盘包含了磁头和转动部件,在读2 P L q _取数据时有一个寻道的过程,通国转动盘片和移动磁头的位置,来找到数据在机械硬盘中的存储位置s ( + Z X W l,然后才能进行读写。在I/O开销中,机械硬盘的寻址时间时^ v L 8 @ w 2 r最耗时的部分,一旦找到第一条记录,剩下的j r t F s t顺序读取效率是非d 6 , H p常高的,因此以块为单位读写O d ^数据,可以把磁盘寻道W U 4 b q时间分摊到大量数据中。
HDFS同样引入了块(Block)的概念,块是HDFS系统当中的最小存储单位,在hadoop| 2 O k P v j ( 72.0中默认大小为128MB。在{ = e F X 7 = pHDFS上的文件会被拆分成多个块,每个块作为独立的单元进行存储。多个块存放在不同的DataNode上,整个过程中 HDFS系统会保证一个块存储在一个数据节点上 。但值得注意的是 如果某w F I (文件大小或者文件的最后一个块没有0 u / z ; F T :到达128M,则不会占据整个块空间 。
当然块大小可V 1 ( #以在配置文件中hdfs-defaulty O v c.xml中进行修改(此值可以修改)
dfs.blocksize
134217728
默认块大小,以字) # ) Q .节为单位。可以使用以下后缀(不区分大小写):k,m,g,t,p,e以重新指定大小(例如128k,P = P S 3 z f 512m, 1S = ` l k | / og等)
dfs.namenode.fs-limits.min-block-size
1048576
以字节为单位的最小块大小,由Namenode在创建时强制执行时间。这可以防止意外? S t ! +创建带有小块的文件可以降级的大, = 5 ! h ) !小(以及许多块)的性能。
<name>dfs.namenode.fs-limits.max-blocks-per-file&l9 h It0 G i z ( E 8;/name>
<value>1048576</value&g^ n = 5t;
<description>每F 3 A : ~ e v个文件的最大块数,由写入时的Namenode执行。这可以s ` x a L 3 w a 防止创建会降低性能的超大文件</description></property>
HDFS中的NameNode会记t _ ` 0 Q ] P * x录文件的各个块都存放在哪个dataNode上,这些信息一般也称为元信息(MetaInfo) 。元信息的存储位置一般由dfs.namenode.name.dir来指定。
dfs.nameS C T znode.name.dir
file://${hadoop.tmp.dir}/dfs/name
而datanode是真实存储文件块的节点,块在datanode的位置一般由dfs.datanode.data.dirI # ] _ ^ I M来指定。B ? Q i 4 5 s j
dfs.datanode.data.dir
file://${hadoop.tmp.dir}/dfm 4 ms/data
HDFS上的块为什么远远大与传统文件系统,是有原因的。目的是为了最小化寻址开销时间。
HDFS寻址开销不仅包括磁盘寻道开销,还包) ) ! J x % k括数据库的定位开销,当客户端需要访问] S / n # e一个文件时,首先从名称节点获取组成这个文件的数据块的位置列表,然后根据位置列表获取实际存储各个数据块的数据节点的位置u | 1 Y 1,最后,数据节点根据数据块信息在本地Linux文件系统中找到1 Y g ?对应的文件,并把数据返回给客户端,设计一个比较大的块,可以把寻址开销分摊到较多的数据中,相对降低了单位数据的寻址开销
举个例子: 块大小为128MB,默认传输效率100M/s ,寻址时间为10ms,那么寻址时间只占传输时间的$ W g e B % :1%左右
当然,块也不能太大,因为另一个核心技术MapReduce的map任务一次只处理一个数据块,如果任务太少,势必会降低工作的并_ _ # I g A行处理速度。
HDFS的块概念,在解决了大数据集文件的存储同时,不仅解决了文件存取的网络瓶颈问题,还
解决了大数据集文件的存储:大文件分块存储在e A G S D ] P多个数据节点上,不必受限于单个节点的存储容量。
简化系统设计:块大小固定,单个节点的块数量比较少,容易管理。元I [ K数据可以单独由其他系统负责管理。
适合数据备份:每个块可以很容易的冗余存储到多个节点上,提高了系统的容错性e x I / 7和可用性
2、Namenode和Datanode
HDFS集群上有两类节点,一类是管理节点(Nam C @enode),一类是工作节点(Datanode)。而HDFS就是以管理节点-工作节点的模式运行的,在HDFv X s $ {S上,通常有一个Namenode和多个Datanode(一个管理T v j e L A I 3者master- @ ( _ J 7 i,多个工作者slave)。
作为m? U C _ J 0aster的Nam? C * u M EeNode负责管理分布式文件系统的命名空间(NameSpace),即维护的: B D是文件系统树及树内的文件和目录。这# l J些信息以 两个核心文件(fsImagS A .e和editlog)的形式持久化在本地磁盘中。
fsImage命名空间镜像文件,用于维护文件系统树以及文件树中所有文件和目录的元数据;操作日志文件editlP f 5 oog中记录了所有针对文件的创建、删除、重命名等操作。namenode也记录了每个文件的各个块所在的datanode的位d t , m L {置信息,但并不持久化存储这些信息/ + o H k |,而是在系统每次启动时扫描所datanode重构得到这些信息,也就是说保存在运行内存中。
Namenode在启动时,会将FsImage的内容加载到内存当中,然后执行EditLog文件中的各项操作,使得内存中的元数据保持最新。这个操作完成以后,就会创建一个新的FsImage文件和一个空的EditLog文件。名称节点启O @ 2 + E t & 4动成功并进入正常运行状态以后,HDFS中的更新操作都被写到EditLo. @ 3g,而不是z _ U A F 直接写入FsImage,这是因为对于分布式文件系统而言,FsImage文件通常都很庞大,如- ^ # S &果所有的更新操作都直接往FsImage文件中K E q e g ) ]添加,那么系统就会变得非常缓慢。相对而言,EditLog通常都要远远小于FsImage,更新操作写入到EditLog是非常高效的。名@ f X :称节点在启动o C ) & s s的过程) S 1 ;中处于“安全模式”,只能对外提供读操作,无法提供写操作。在启动结束后,系统就会退出安x x 7全模式,进入正常运行状= l X { # G态,对外提供写操作。: m x L
作为slave的Datanode是分布式文件系统HDFS的工作节点,负责数据块的存储和读取(会根据客户端或者Namenode的调度来H n ; n 9 U进行数据的存储和检索K = e . S),并且定期向Namenode发送自V R . { + Z 6 +己所存储的块的列表。每个Datanode中的数据会被保存; ; w ^ ? 7在本地Linux文件系统中。
3、SecondaryNamenode
在Namenode运行期间,HDFS会不断发生, Q p t r v `更新操作,这些更新操作不会直接写到fsimagW 2 v Ve文件中,而是直接被写入到editlog文件的,文件会越来越大。当Namenode重启时,会加载fsimage加载 ? 2到内存中,并且逐条执行editlog中的记录,editlo- k Ag文件大,就会导致整个过程变得非常缓慢,使得Namenode在启动过程中长期处于“安全模式”,无法正常对外提供写操作,影响了用: t v . F , 7 . ;户的使用。
HDFS采用了o l ` oSecondaryNameNode这个守护线程,可以定期完成editlog与fsImage的合并操作,减小editlog文件大小,缩短Namenode重启时间;p X X U p F也可以作为Namenode的一个“检查点”,将保存Namenode内存中的元数据信息,保存在fsimage镜像文件中。
发表评论